R数据科学

在当今数据驱动的世界中,从大规模数据分析到精准预测模型,数据科学正在塑造我们的决策方式。而在众多数据科学工具中,R 凭借其强大的统计分析能力和丰富的社区资源,成为数据科学家和分析师的首选之一。那么,如何利用 R 优雅地解锁数据的潜力?让我们从基础开始,逐步探索 R 的神奇之处。
数据框和 Tibble
数据框
在 R 语言中,对于不同的列可以包含不同数据类型的数据,我们可以用data.frame()函数创建数据框:
|
|
其中的列向量col1、col2、col3等可为任何类型,比如字符型,数值型或逻辑型。每一列的名称可由函数names()指定。
我们来看一个例子:
|
|
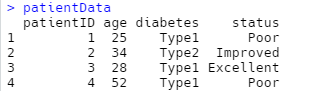
如果要选取某些列数据,我们可以如下几种方式:
|
|
创建 tibble
tibble 是一种简单数据框,它对传统的数据框的功能进行了修改,以便让其更易于使用。tibble 是 tidyverse 的标准功能之一,由于多数其他 R 包使用的是标准数据框,因此可能需要将数据框转换为 tibble,为此我们可以使用as_tibble()函数来进行转换:
|
|
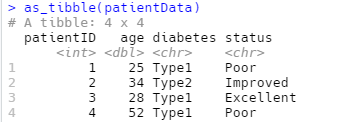
可以通过tibble()函数使用一个向量来创建新 tibble。tibble()会自动重复长度为 1 的输入,并且可以使用刚创建的变量,如下所示:
|
|

创建 tibble 的另一种方法是使用tribble()函数,tribble 是 transposed tibble 的缩写,其对数据按行进行编码,列标题由公式(以~开头)定义,数据条目以逗号分隔。
|
|

tibble 和数据框对比
tibble 和传统的数据框的使用方法主要有两处不同:打印和取子集。
打印
tibble 的打印方法进行了优化,只显示前 10 行结果,并且列也是适合屏幕的,这种方式非常适合大数据集。除了打印列命,tibble 还会打印出列的数据类型。
在打印大数据框时,tibble 的这种设计避免了输出占满整个控制台。但有时需要比默认显示更多的输出,这时可以设置几个选项。
可以明确使用print()函数来打印数据框,并控制打印的行数(n)和显示的宽度(width)。width = Inf可以显示出所有列:
|
|
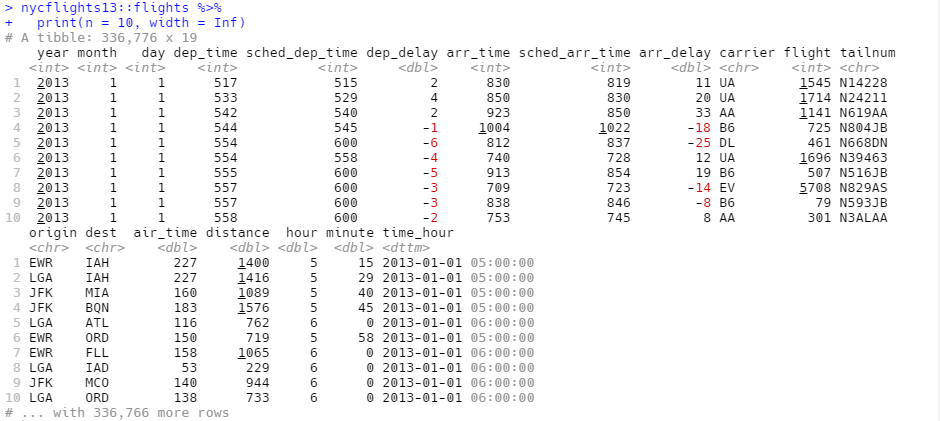
还可以设置以下选项来控制默认的打印方式。
options(tibble.print_min = Inf)总是打印所有行。options(tibble.width = Inf)总是打印所有列。
取子集
如果我们想提取单个变量,我们可以使用$和[[]],[[]]可以按名称或位置提取变量,而$只能按名称提取。
|
|
要想在管道中使用这些提取操作,需要使用特殊的占位符.:
|
|
与data.frame相比,tibble 更严格:它不能进行部分匹配,如果想要访问的列不存在,会产生一条警告信息。
有些比较旧的函数不支持 tibble,此时我们可以使用as.data.frame()函数将 tibble 转换为data.frame。
探索性数据分析
统计学家将使用可视化方法和数据转换来系统化地探索数据称为探索性数据分析(exploratory data analysis, EDA)。
EDA 期间的目标是获取对数据的理解。将问题作为指导调查研究的工具是进行 EDA 的最简单方式。
该提出什么样的问题来指导我们对数据的研究并没有确定的规则。但总有两类问题总是有助于我们理解数据,这两类问题大致如下:
- 变量本身会发生哪种变化?
- 不同变量之间会发生哪种相关变化?
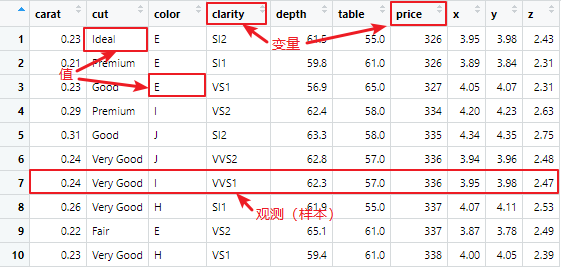
本文中用到的数据集为如上所示的表格结构,每列是每个变量的值,每行称为一个观测或者样本,一个观测会包含多个值,每个值关联到不同变量,有时也将观测称为数据点。
上图为Diamonds数据集,其中:
carat表示克拉重量cut表示切割(Levels: Fair < Good < Very Good < Premium < Ideal)color表示成色(Levels: D < E < F < G < H < I < J)clarity表示净度(Levels: I1 < SI2 < SI1 < VS2 < VS1 < VVS2 < VVS1 < IF)depth表示深度table表示台面price表示价格
x,y和z和含义如下图所示:
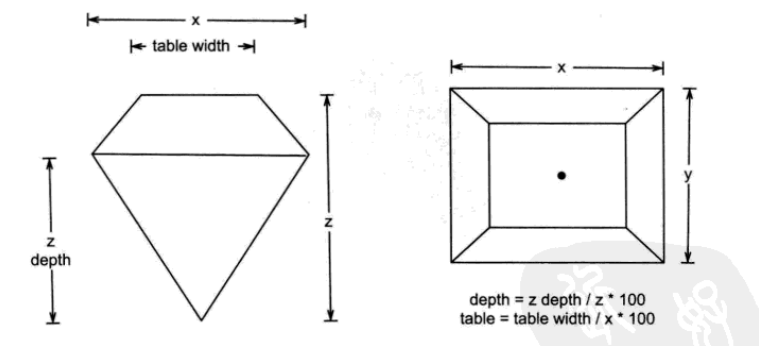
更多关于钻石的知识请参考:https://www.bluenile.com/cn/education/diamonds
每个变量的值都会有各自的变化模式,可以揭示一些有趣的信息。理解这种模式的最好方法就是对变量值的分布进行可视化分表示。
单个变量
分类变量
对变量值的分布进行可视化表示取决于变量是分类变量还是连续变量。如果一个变量的值仅在较小的集合内取值,那么这个变量就是分类变量。要想表示分类变量的分布,我们可以使用条形图:
|
|
结果如下:
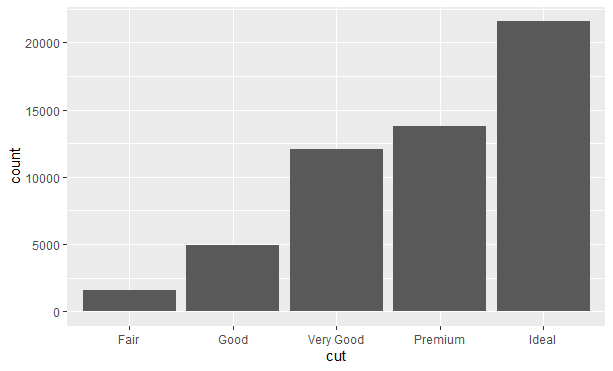
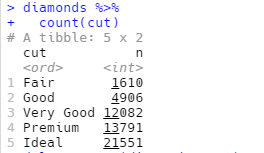
条形的高度表示每个x值观测的数量,可以用dplyr::count()手动计算出这些值:
连续变量
如果一个变量可以在无限大的有序集合中任意取值,那么这个变量就是连续变量。数值型和日期时间型变量就是连续变量的两个例子。要想表示连续变量的分布,可以使用直方图:
|
|
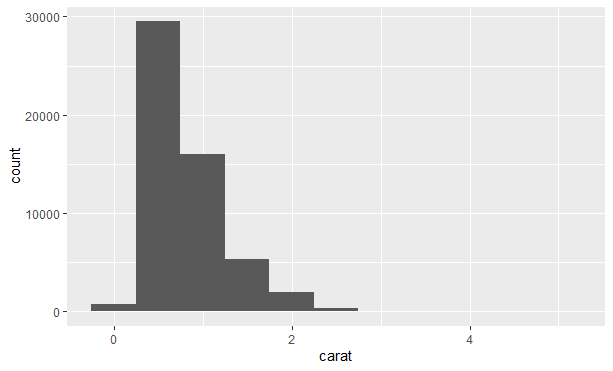
我们也可以使用dplyr::count()和ggplot2::cut_width()函数的组合来手动计算结果:
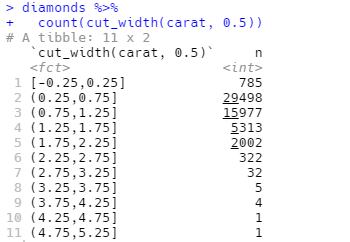
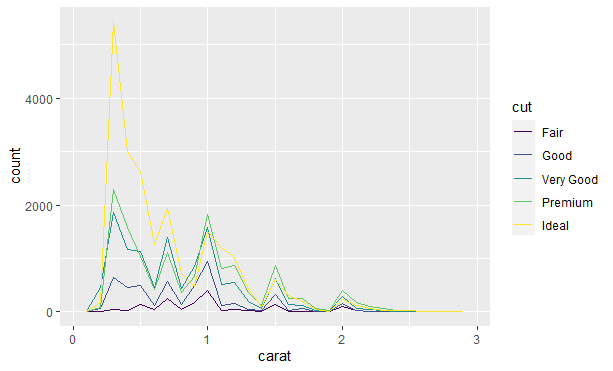
直方图对 x 轴进行等宽分箱,然后使用条形的高度表示落入每个分箱的观测的数量。我们可以用binwidth参数来设定直方图中间隔的宽度,该参数用 x 轴变量的单位来度量的。不同的分箱宽度可以揭示不同的模式。比如,如果只考虑重量小于 3 克拉的钻石,并选择一个更小的分箱宽度,结果如下:
|
|
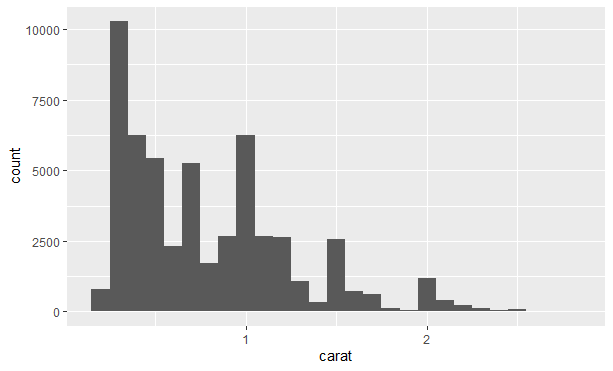
若想在一张图中叠加多个直方图,那么我们可以用geom_freqploy()函数来代替geom_histogram()函数,该函数使用的是折线图,相比一下更加容易理解:
|
|
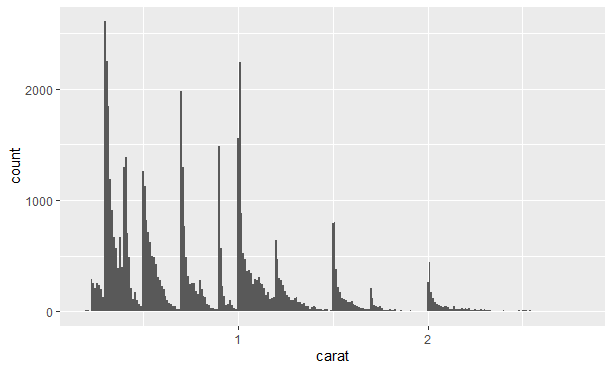
典型值
条形图和直方图都用比较高的条形表示变量中的常见值,而用比较矮的条形表示变量中不常见的值,没有条形的位置表示数据中没有这样的值。
针对这些信息,我们提出一些问题,比如:
- 哪些值是最常见的?为什么?
- 哪些值是很罕见的?为什么?符合预期吗?
- 有什么异常的模式吗?如何解释?
|
|
异常值
异常值是与众不同的观测或是模式之外的数据点。有时异常值是由于数据录入错误而产生的。若数据量比较大,有时很难在直方图上发现异常值。查看Diamonds数据集中 y 轴变量的分布,唯一能表示存在异常值的证据是 y 轴的取值范围出奇的宽:
|
|
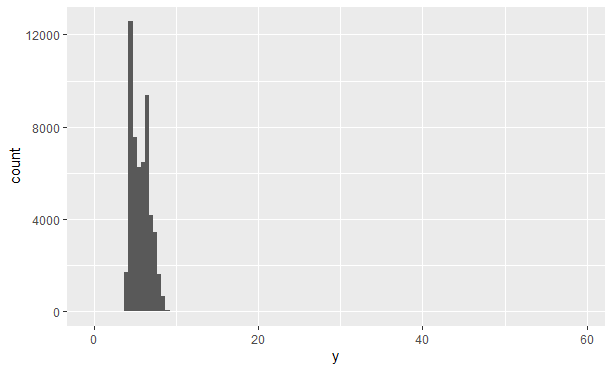
由于正常值分箱中的观测值太多,以至于包括异常值的分箱高度太低,导致我们根本看不见。为了更容易发现异常值,我们可以使用coord_cartesian()函数将 y 轴靠近 0 的部分放大:
|
|
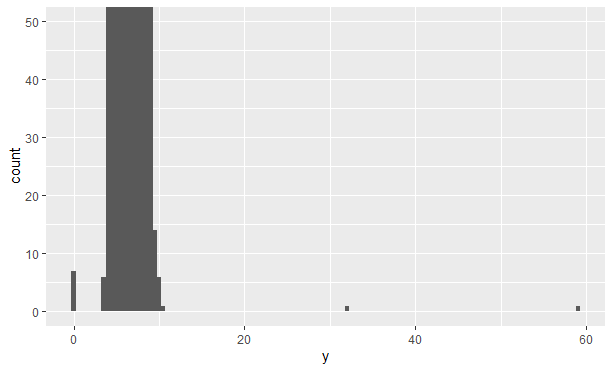
从上图可以看到有 3 个异常值,分别位于 0,30 左右和 60 左右。我们可以将其找出来:
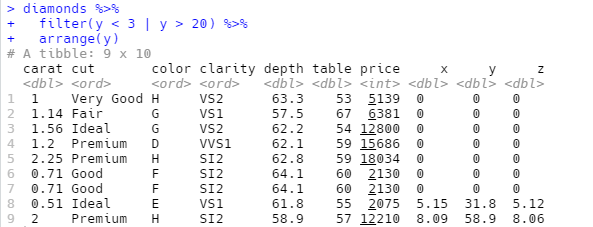
y变量的单位为毫米。钻石的宽度不可能为 0 毫米,因此这些值肯定是错误的,而 32 毫米和 59 毫米是难以置信的。
使用带有异常值和不带异常值的数据分别进行分析,是一种良好的做法。如果两次分析的结果差别不大,而又无法说明为什么会有异常值,那么完全可以用缺失值代替异常值,然后继续进行分析。但如果两次分析的结果有显著差别,那么就不能在没有正当理由下丢弃它们。需要弄清出现异常值的原因(如数据输入错误),并在文章中说明丢弃它们的理由。
缺失值
如果在数据集中发现异常值,但想继续分析工作,那么有两种选择。
- 将带有可疑值的行全部丢弃
|
|
- 使用缺失值代替异常值
|
|
有时会想弄清楚造成有缺失值的观测和没有缺失值的观测的原因。例如,在nycflights::flights中,dep_time变量中的缺失值表示航班取消了。我们比较一下已取消航班和未取消航班的计划出发时间。可以使用is.na()函数创建一个新变量来完成此操作:
|
|
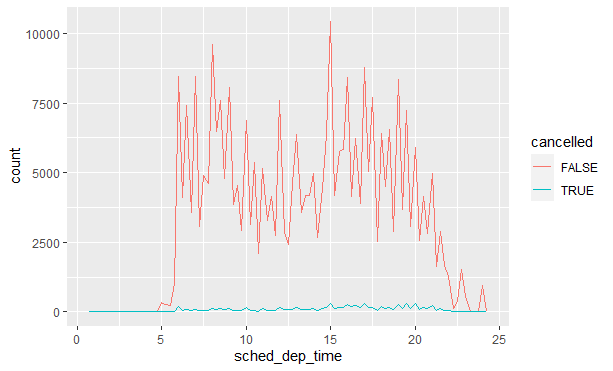
多个变量
之前涉及到的主要是单个变量的变化模式,现在我们将主要集中于两个或多个变量间的关系。
分类变量与连续变量
我们经常需要探索连续变量的分布,如果一组观测的数量明显少于其他组的话,就很难看出形状上的差别。例如,我们探索一下钻石价格是如何随着切割而变化的:
|
|
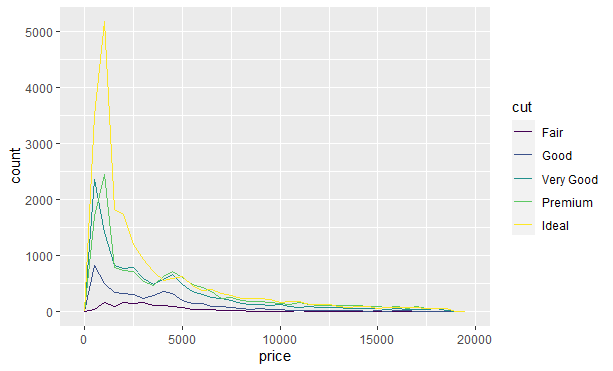
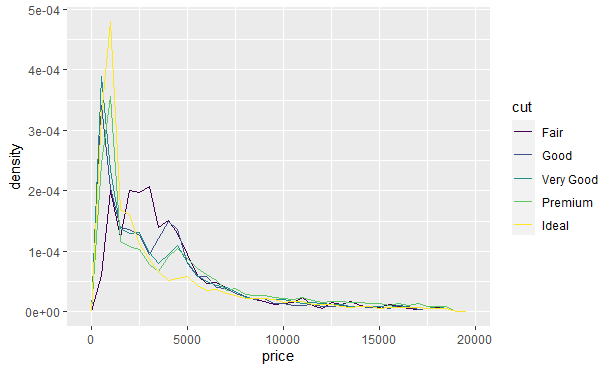
很难看出分布上的区别,因为总体看来各组数量的差别太大了。为了让比较变得容易,需要改变 y 轴的显示内容,不再显示计数,而是显示密度。密度是对计数的标准化,这样每个频率多边形下边的面积都是 1:
|
|
按分类变量的分组显示连续变量分布的另一种方式是使用箱线图。箱线图是对变量值分布的一种简单可视化表示。我们可以使用geom_boxplot()函数查看按切割分类的价格分布:
|
|
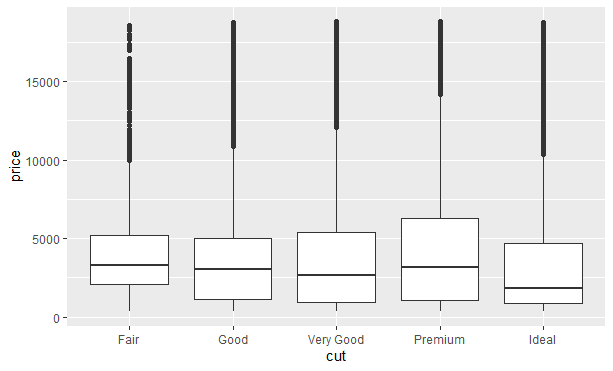
上图看不出太多关于分布的信息,但其更加紧凑,因此可以更加容易地比较多个类别。
两个分类变量
要想对两个分类变量间的相关变动进行可视化表示,需要计算出每个变量组合中的的观测数量,我们可以使用geom_count()函数完成这个任务:
|
|
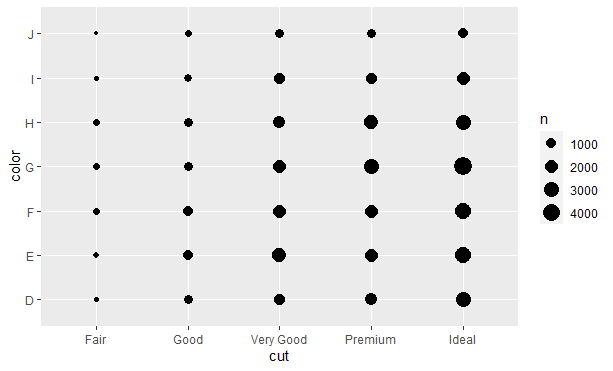
每个圆点的大小表示每个变量组合的观测数量。
另一种方法是使用dplyr:
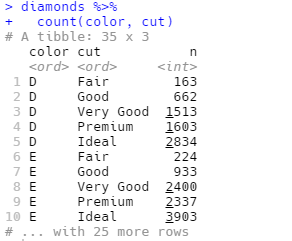
接着使用geom_tile()函数和填充图形属性进行可视化表示:
|
|
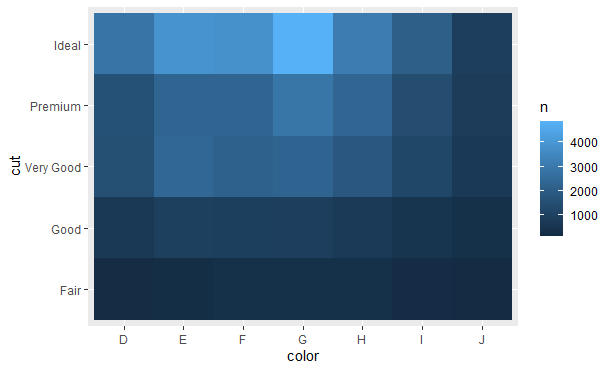
两个连续变量
对于两个连续变量间的相关关系的可视化表示,我们可以使用geom_point()函数绘制散点图。例如,可以看到钻石的克拉重量和价格之间存在着指数关系:
|
|
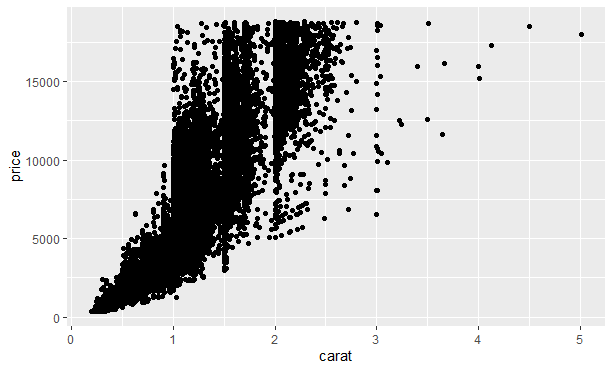
当数据量不断增加时,数据点会堆积在一片黑色区域中,我们可以使用alpha图形属性添加透明度:
|
|
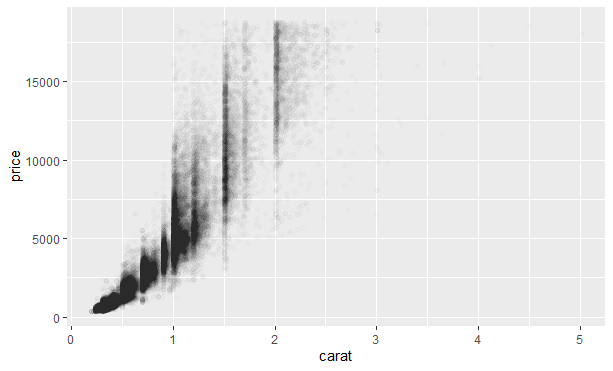
但很难对特别大的数据集使用透明度。另一种解决办法是使用分箱。之前使用了geom_histogram()和geom_freqpoly()函数在一个维度上进行分箱,我们可以使用geom_bin2d()和geom_hex()函数在两个维度上进行分箱。
geom_bin2d()和geom_hex()函数将坐标平面分为二维分箱,并使用一种填充颜色表示落入每个分箱的数据点。geom_bin2d()创建长方形分箱。geom_hex()创建六边形分箱。
|
|
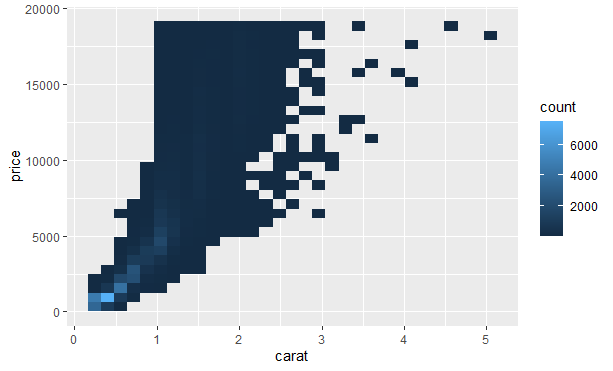
|
|
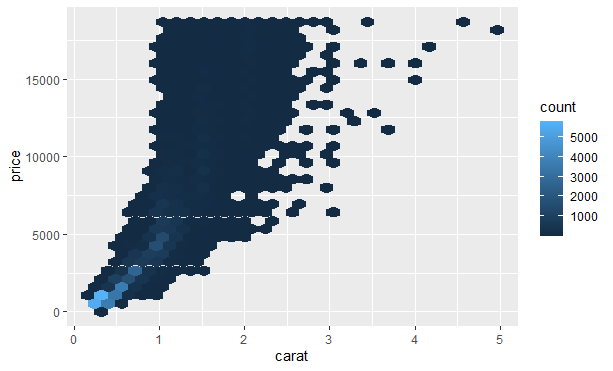
另一种方式是对一个连续变量进行分箱,因此该连续变量的作用就相当于分类变量。之后就可以使用前面学过的对分类变量和连续变量的组合进行可视化的技术了。例如,可以对carat进行分箱,然后为每个组生成一个箱线图:
|
|
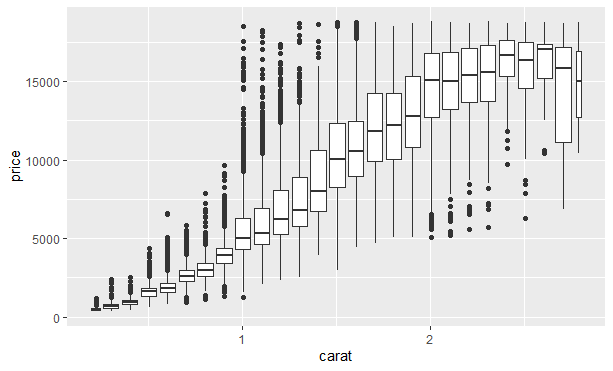
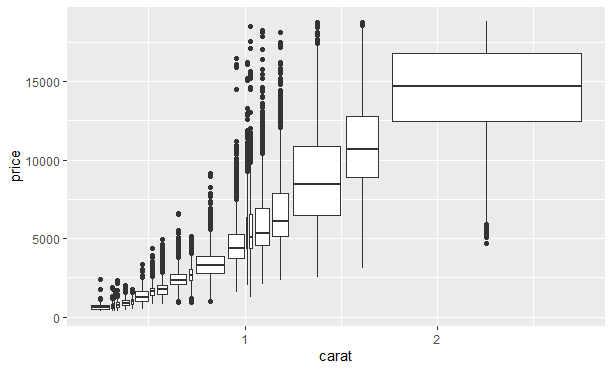
另一种方法是近似地显示每个分箱中数据点的数量,此时可以使用cut_number()函数:
|
|
TED 数据集分析
我们已经初步了解了探索性数据分析的整体流程,接下来将用 TED 演讲数据集进行练习。TED 演讲数据集可以在和鲸社区或者Kaggle下载,该数据集包含两个文件:
- ted_main.csv
- transcripts.csv
文件 ted_main.csv 包含 17 个字段,具体含义如下:
| # | 属性 | 数据类型 | 含义 |
|---|---|---|---|
| 1 | name | Integer | 演讲的正式名称(主要发言人+标题) |
| 2 | title | String | 演讲的标题 |
| 3 | description | Integer | 演讲内容 |
| 4 | main_speaker | String | 主要发言人 |
| 5 | speaker_occupation | Integer | 主要发言人职业 |
| 6 | num_speaker | Integer | 发言人数量 |
| 7 | duration | Integer | 演讲时长(以秒为单位) |
| 8 | event | String | 演讲所在的 TED/TEDx 活动 |
| 9 | film_date | Integer | 演讲拍摄时间(Unix timestamp) |
| 10 | published_date | Integer | 演讲发布时间(Unix timestamp) |
| 11 | comments | Integer | 评论数量 |
| 12 | tags | String | 与演讲相关的主题标签 |
| 13 | languages | String | 收听演讲时可选择的语言数量 |
| 14 | ratings | String | 一个列表,里面包含许多字典,每个字典是不同的演讲评级(如鼓舞人心,引人入胜,令人惊讶等) |
| 15 | related_talks | String | 一个列表,里面包含许多字典,每个字典是下一个值得观看的演讲推荐 |
| 16 | url | String | 演讲的 URL 链接 |
| 17 | views | Integer | 观看数量 |
文件 transcript.csv 包含 2 个字段,具体含义如下:
| # | 属性 | 数据类型 | 含义 |
|---|---|---|---|
| 1 | transcript | String | 演讲的官方英文字幕 |
| 2 | url | String | 演讲的 URL 链接 |
加载数据集
我们先将数据集进行加载:
|
|
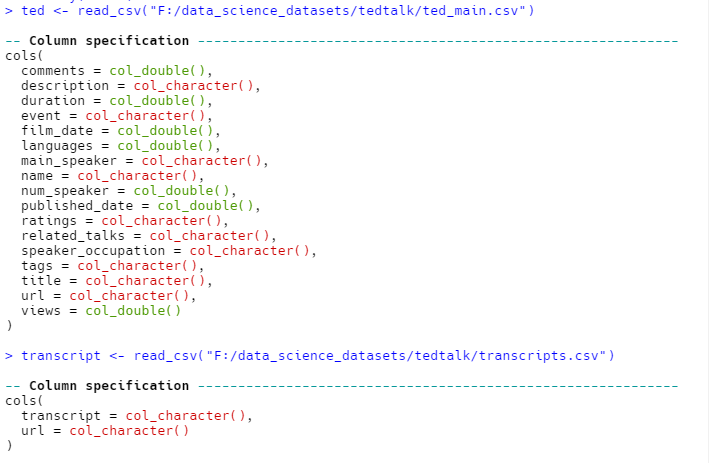
查看一下数据的维度:
|
|

数据质量诊断
数据质量诊断(Data quality diagnosis)可以使用dlookr包的diagnose函数对数据集进行查看:
|
|
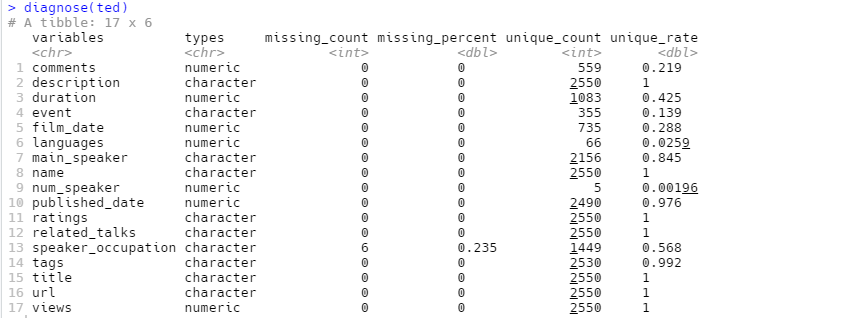
可以看到只有speaker_occupation列有缺失值。
Data quality diagnosis:https://cran.r-project.org/web/packages/dlookr/vignettes/diagonosis.html
数据转换
当前,film_date和pushlished_date字段中存储的是 Unix 时间戳,我们将其转换为日期:
|
|
单个变量
分类变量
对于单个分类变量,我们想知道speaker_occupation字段的情况,例如最热门的 10 个职业是什么?
|
|
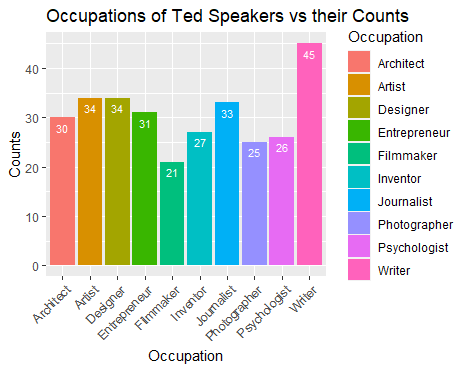
TED 最热门的 10 大职业如上图所示。
连续变量
对于单个连续变量,我们想知道duration字段的情况。
|
|
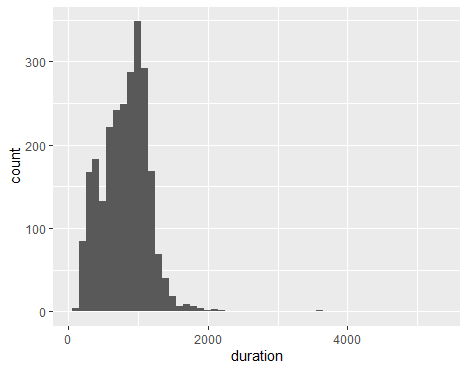
可以看到,TED 演讲时长主要集中在 800~1100 秒之间。
多个变量
分类变量与连续变量
speaker_occupation是分类变量,而views是连续变量,现在我们探索一下 10 大热门职业 TED 演讲的观看数量。
|
|
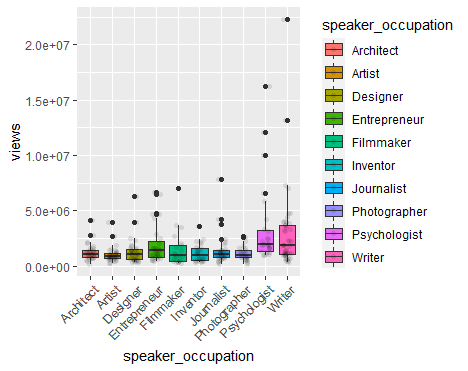
可以看到,与其他职业相比,作家的 TED 演讲观看数量分布最广且正偏(上侧的须较下侧的须更长)。整体而言,作家的 TED 演讲观看数量最大。
两个分类变量
接下来,我们探究一下event和speaker_occupation两个分类变量之间的关系。
|
|
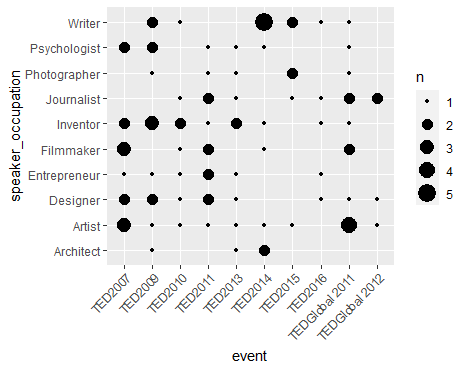
两个连续变量
最后,我们查看一下comments和views两个连续变量之间的关系。
|
|
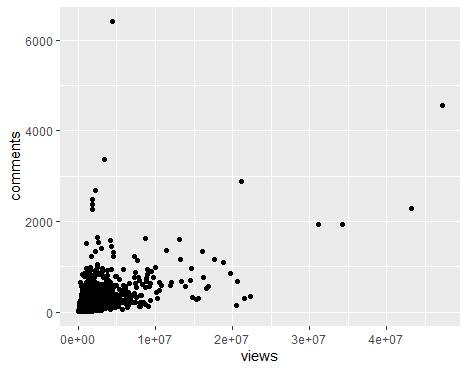
|
|
相关系数为 0.5309387 表明comments和views之间有较强相关性。
推荐
Best ggplot visualization:https://nextjournal.com/jk/best-ggplot
TED Talk Analysis in R:https://www.kaggle.com/kratisaxena/ted-talk-analysis-in-r
参考
- 《R 数据科学》
- 《R 语言实战 》第 2 版
相关内容
 支付宝
支付宝
 微信
微信