OpenCV简明教程

无论我们想要学习如何将面部识别应用于视频流,还是用深度学习构建图像分类器,或者做其他一些有关图像识别的有趣项目,可能都会需要学一些 OpenCV 的知识,本文将做简单介绍。
加载和显示图像

保存上面的图片,打开你最爱的编辑器,输入以下代码:
|
|
第 3 行,使用cv2.imread()导入图像。
第 4 行,使用cv2.imshow()显示图像。窗口会自动调整为图像大小。第一个参数是窗口的名字,然后是我们的图像。
第 5 行,使用cv2.waitKey()等待键盘输入。
运行一下,结果如下所示:

获取并修改像素值
我们可以先查看一下图像的形状,
|
|
image.shape可以获取图像的形状。返回的是一个包含行数(高),列数(宽),通道数的元组。
可以根据像素的行、列坐标获取其像素值。对于 BGR 图像来说,返回值为 B,G,R 的值。对灰度图像来说,返回值为其灰度值。
|
|
可以用类似的方式修改像素值,
|
|
图像 ROI
有时我们需要对一幅图像的感兴趣的区域(Regions of Interest,ROI)进行操作。比如,我们要检测一幅图像中眼睛的位置,我们首先应该在图像中找到脸,再在脸的区域中找眼睛,而不是直接在一幅图像中搜素。ROI 也是通过索引获得,其实就相当于数组切片。
|
|
结果如下:

图像缩放
OpenCV 提供的函数cv2.resize()可以改变图像的尺寸大小。
|
|

旋转图像

对一个图像旋转角度 $\theta$,需要用到下面形式的旋转矩阵。
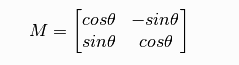
OpenCV 允许我们在任意地方进行旋转,于是旋转矩阵的形式应该改为:
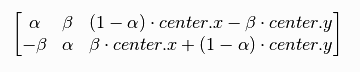
其中:
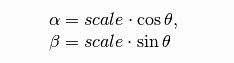
为了构建这个旋转矩阵,OpenCV 提供了一个函数:cv2.getRotationMatrix2D()。
以下便是在不缩放的情况下将图像旋转 90 度。
|
|
第 5 行,第一个参数为旋转中心,第二个参数为旋转角度,第三个为旋转后的缩放因子。
第 6 行,第三个参数是输出图像的尺寸。

图像模糊
在许多的图像处理过程中,我们必须模糊图像以减少高频噪声,使算法更容易检测和理解图像的实际内容。在 OpenCV 中模糊图像非常容易,有很多方法可以用。
|
|
第 4 行,我们使用了高斯模糊,用了11 x 11的核。

较大的核会产生更模糊的图像,较小的核将产生没那么的模糊图像。
绘图函数
本节我们将在导入的图像上画矩形,圆,线以及添加文字。但值得注意的是,这些操作会影响到原始导入的image,为了避免这样,我们可以用image的副本进行操作。
|
|
第 5 行,设置的参数如下:
img:想要绘制图像的那幅图像,这里是output。pt1:矩形左上角坐标,这里是(163, 30)。pt2:矩形右下角坐标,这里是(244, 124)。color:BGR 元组,这里是红色(0,0,255)。thickness:线条粗细(如果一个闭合图形设置为负数,那么这个图形就会被填充),这里是2。
结果如下:

接下来,我们在猫咪的图像上画一个圆。
|
|
要画圆的话,需要指定圆形的圆心坐标和半径大小。
第 5 行,我们指定圆心为(35,25),半径大小为20。其他参数含义,和画矩形时一样。

画线的话,我们只需要指定起点和终点即可。
|
|
第 5 行,我们指定起点为(35,25),终点为(125,69)。
结果如下:

我们可能经常需要在图像上添加文字,比如在进行人脸识别的时候,需要在人的脸上绘制出他们的名字。可以使用 OpenCV 的cv2.putText()函数在图像上添加文字。
|
|
第 5~6 行,设置的参数如下:
img:想要绘制图像的那幅图像,这里是output。text:要绘制的文字内容,这里是Sasaki Nozomi。pt:绘制的位置,这里是(10,25)。font:字体类型,这里是cv2.FONT_HERSHEY_SIMPLEX。scale:字体大小乘数,这里是0.7。color:字体颜色,这里是红色(0,0,255)。thickness:字体粗细,这里是2。
如下图所示,“Sasaki Nozomi”绘制在图像上,

参考
 支付宝
支付宝
 微信
微信