BeautifulSoup是啥?它是一个可以从 HTML 或 XML 文件中提取数据的 Python 库。它能通过我们喜欢的转换器实现文档导航,查找和修改。
安装 BeautifulSoup
可以通过pip来安装,包的名字的是beautifulsoup4。
1
pip install - i https : // pypi . douban . com / simple beautifulsoup4
安装解析器
BeautifulSoup除了支持 Python 标准库中的 HTML 解析器之外,还支持一些第三方的解析器,比如lxml 。可以按下列方式来安装 lxml:
1
pip install - i https : // pypi . douban . com / simple lxml
另一个可供选择的解析器是纯 Python 实现的html5lib ,可以按下列方式来安装 html5lib:
1
pip install - i https : // pypi . douban . com / simple html5lib
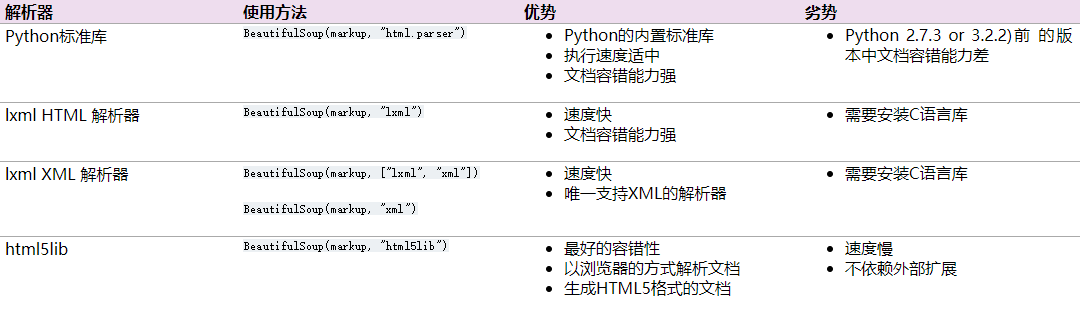
下表列出了主要的解析器以及它们的优缺点:
如何使用
将一段文档传入BeautifulSoup的构造方法就能得到一个文档对象,可以传入一段字符串或一个文件句柄。
1
2
3
4
5
from bs4 import BeautifulSoup
soup = BeautifulSoup ( open ( "index.html" ))
suop = BeautifulSoup ( "<html>data</html>" )
如果手动指定解析器的话,BeautifulSoup会选择指定的解析器来解析文档。
对象的种类
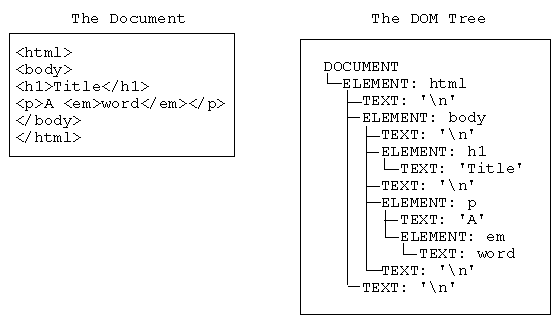
BeautifulSoup将复杂的 HTML 文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为 4 中:Tag,NavigableString,BeautifulSoup,Comment。
Tag
Tag对象与 XML 或 HTML 文档中的 tag 相同:
1
2
3
4
5
6
from bs4 import BeautifulSoup
soup = BeautifulSoup ( '<b class="boldest">Extremely bold</b>' )
tag = soup . b
type ( tag )
# <class 'bs4.element.Tag'>
Tag有很多方法和属性,比如遍历文档树和搜索文档树。现在介绍一下 tag 中最重要的属性:name和attributes。
Name
每个 tag 都有自己的名字,通过.name来获取:
如果改变 tag 的 name 将会影响所有通过当前BeautifulSoup对象生成的 HTML 文档:
1
2
3
4
5
6
7
tag . name = "blockquote"
tag
# <blockquote class="boldest">Extremely bold</blockquote>
tag . name = "ironman"
tag
# <ironman class="boldest">Extremely bold</ironman>
Attributes
一个 tag 可能有很多个属性。tag <b class="boldest">有一个名为class的属性,值为boldest。tag 的属性的操作方法与字典相同:
1
2
3
tag [ 'class' ]
# ['boldest']
也可以直接.取属性,比如:.attrs:
1
2
3
tag . attrs
# {'class': ['boldest']}
tag 的属性可以被添加,删除或修改,和字典一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
In [ 13 ]: tag [ 'class' ]
Out [ 13 ]: [ 'boldest' ]
In [ 14 ]: tag [ 'class' ] = 'verybold'
In [ 15 ]: tag [ 'id' ] = 1
In [ 16 ]: tag
Out [ 16 ]: < ironman class = "verybold" id = "1" > Extremely bold </ ironman >
In [ 17 ]: del tag [ 'class' ]
In [ 18 ]: del tag [ 'id' ]
In [ 19 ]: tag
Out [ 19 ]: < ironman > Extremely bold </ ironman >
In [ 20 ]: tag [ 'class' ]
KeyError
In [ 21 ]: tag . get ( 'class' )
多值属性
HTML 定义了一系列可以包含多个值的属性。最常见的多值属性是class(一个 tag 可以有多个 CSS 的class)。在BeautifulSoup中多值属性的返回类型是 list:
1
2
3
4
In [ 22 ]: css_soup = BeautifulSoup ( '<p class="body strikeout"></p>' )
In [ 23 ]: css_soup . p [ 'class' ]
Out [ 23 ]: [ 'body' , 'strikeout' ]
如果某个属性看起来好像有多个值,但在任何版本的 HTML 定义中都没有被定义为多值属性,那么BeautifulSoup会将这个属性作为字符串返回
1
2
3
4
In [ 25 ]: id_soup = BeautifulSoup ( '<p id="my id"></p>' )
In [ 26 ]: id_soup . p [ 'id' ]
Out [ 26 ]: 'my id'
NavigableString
字符串常被包含在 tag 内。BeautifulSoup用NavigableString类来包装 tag 中的字符串:
1
2
3
4
5
6
7
8
In [ 27 ]: tag
Out [ 27 ]: < ironman > Extremely bold </ ironman >
In [ 28 ]: tag . string
Out [ 28 ]: 'Extremely bold'
In [ 29 ]: type ( tag . string )
Out [ 29 ]: bs4 . element . NavigableString
NavigableString 对象支持遍历文档树 和搜索文档树 中定义的大部分属性, 并非全部。
BeautifulSoup
BeautifulSoup对象表示的是整个文档的内容。大部分时候,可以把它当作Tag对象,它支持遍历文档树 和搜索文档树 中定义的大部分方法。
Tag,NavigableString,BeautifulSoup几乎覆盖了 html 和 xml 中的所有内容,但是还有一些特殊对象。
1
2
3
4
5
6
7
8
In [ 30 ]: markup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"
In [ 31 ]: soup = BeautifulSoup ( markup , 'lxml' )
In [ 32 ]: comment = soup . b . string
In [ 34 ]: type ( comment )
Out [ 34 ]: bs4 . element . Comment
Comment对象是一个特殊类型的NavigableString对象。 soup = BeautifulSoup(markup, 'lxml')中的lxml用于指定解析器。
搜索文档树
BeautifulSoup定义了很多搜索方法,这里着重介绍 2 个:find_all()和select()。
以“爱丽丝”文档作为例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
In [ 40 ]: html_doc = """
...: <html><head><title>The Dormouse's story</title></head>
...:
...: <p class="title"><b>The Dormouse's story</b></p>
...:
...: <p class="story">Once upon a time there were three little sisters; and their names were
...: <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
...: <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
...: <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
...: and they lived at the bottom of a well.</p>
...:
...: <p class="story">...</p>
...: """
In [ 41 ]: from bs4 import BeautifulSoup
In [ 42 ]: soup = BeautifulSoup ( html_doc , 'lxml' )
使用find_all()类似的方法可以查找到想要查找的文档内容。
过滤器
在介绍find_all()方法之前,先介绍一下过滤器的类型,这些过滤器贯穿整个搜索的 API。过滤器可以被用在 tag 的 name 中,节点的属性中,字符串中或它们的混合中。
字符串
最简单的过滤器是字符串。在搜索方法中传入也给字符串参数,BeautifulSoup会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有<b>标签:
1
2
In [ 43 ]: soup . find_all ( 'b' )
Out [ 43 ]: [ < b > The Dormouse 's story</b>]
正则表达式
如果传入正则表达式作为参数,BeautifulSoup会通过正则表达式的match()来匹配内容。下例中找出所有以 b 开头的标签,这意味着<body>和<b>标签都应该被找到:
1
2
3
4
5
6
7
In [ 44 ]: import re
In [ 45 ]: for tag in soup . find_all ( re . compile ( '^b' )):
... : print ( tag . name )
... :
# body
# b
列表
如果传入列表参数BeautifulSoup会将领与列表中任一元素匹配的内容返回。下列代码将会找到文档中所有<a>和<b>标签:
1
2
3
4
5
6
In [ 46 ]: soup . find_all ([ 'a' , 'b' ])
Out [ 46 ]:
[ < b > The Dormouse 's story</b>,
< a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
True
True可以匹配任何值,以下代码查找到所有的 tag,但不会返回字符串节点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
In [ 47 ]: for tag in soup . find_all ( True ):
... : print ( tag . name )
... :
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
p
方法
如果没有合适的过滤器,还可以定义一个方法,方法只接受一个元素参数,如果这个方法返回True表示当前元素匹配并且被找到,若不是则返回False。
下列方法检验了当前元素,如果包含class属性却不包含id属性则返回True:
1
2
def has_class_but_no_id ( tag ):
return tag . has_attr ( 'class' ) and not tag . has_attr ( 'id' )
将该方法作为参数传入find_all()方法将得到所有<p>标签:
1
2
3
4
5
6
7
8
9
In [ 66 ]: soup . find_all ( has_class_but_no_id )
Out [ 66 ]:
[ < p class = "title" >< b > The Dormouse 's story</b></p>,
< p class = "story" > Once upon a time there were three little sisters ; and their names were
< a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > and
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ;
and they lived at the bottom of a well .</ p > ,
< p class = "story" >...</ p > ]
返回结果中只有<p>标签没有<a>标签,因为<a>标签还定义了id,没有返回<html>和<head>,因为<html>和<head>中没有定义class属性。
下面代码找到所有被文字包含的节点内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
In [ 68 ]: from bs4 import NavigableString
def surrounded_by_strings ( tag ):
return isinstance ( tag . next_element , NavigableString ) and isinstance ( tag . previous_element , NavigableString )
In [ 70 ]: for tag in soup . find_all ( surrounded_by_strings ):
... : print ( tag . name )
... :
# p
# a
# a
# a
# p
find_all()
1
find_all ( name , attrs , recursive , text , ** kwargs )
find_all()方法搜索当前 tag 的所有 tag 子节点,并判断是否符合过滤器的条件。
name 参数
name参数可以查找所有名字为name的 tag,字符串对象会被自动忽略掉。
例如:
1
2
In [ 72 ]: soup . find_all ( "title" )
Out [ 72 ]: [ < title > The Dormouse 's story</title>]
name参数的值可以是任一类型的过滤器,字符串、正则表达式、列表、方法或是True。
keyword 参数
如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字 tag 的属性来搜索。如果包含一个名字为id参数,BeautifulSoup会搜索每个 tag 的id属性。
1
2
In [ 73 ]: soup . find_all ( id = "link2" )
Out [ 73 ]: [ < a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ]
如果传入href参数,BeautifulSoup会搜索每个 tag 的href属性:
1
2
In [ 76 ]: soup . find_all ( href = re . compile ( 'elsie' ))
Out [ 76 ]: [ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ]
搜索指定名字的属性时可以使用的参数值包括:字符串、正则表达式、列表、True。
下例在文档中查找所有包含id属性的 tag,无论id的值是什么:
1
2
3
4
5
In [ 77 ]: soup . find_all ( id = True )
Out [ 77 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
使用多个指定名字的参数可以同时过滤 tag 的多个属性:
1
2
In [ 78 ]: soup . find_all ( href = re . compile ( "elsie" ), id = 'link1' )
Out [ 78 ]: [ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ]
有些 tag 属性在搜索时不能使用,比如 HTML5 中的data-*属性:
1
2
3
4
5
6
7
In [ 79 ]: data_soup = BeautifulSoup ( '<div data-foo="value">foo!</div>' , 'lxml' )
In [ 80 ]: data_soup . find_all ( data - foo = "value" )
File "<ipython-input-80-a766c8a0cac6>" , line 1
data_soup . find_all ( data - foo = "value" )
^
SyntaxError : keyword can 't be an expression
可以通过find_all()方法attrs参数定义一个字典参数来搜索包含特殊属性的 tag:
1
2
In [ 81 ]: data_soup . find_all ( attrs = { 'data-foo' : 'value' })
Out [ 81 ]: [ < div data - foo = "value" > foo ! </ div > ]
按 CSS 搜索
可以通过class_参数搜索指定 CSS 类名的 tag:
1
2
3
4
5
In [ 82 ]: soup . find_all ( 'a' , class_ = "sister" )
Out [ 82 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
class_参数同样接受不同类型的过滤器,字符串,正则表达式,方法或True。
text 参数
通过text参数可以搜索文档中的字符串内容。与name参数的可选值一样,text参数接受字符串,正则表达式,列表,True,方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
In [ 83 ]: soup . find_all ( text = 'Elsie' )
Out [ 83 ]: [ 'Elsie' ]
In [ 84 ]: soup . find_all ( text = [ 'Tillie' , 'Elsie' , 'Lacie' ])
Out [ 84 ]: [ 'Elsie' , 'Lacie' , 'Tillie' ]
In [ 85 ]: soup . find_all ( text = re . compile ( 'Dormouse' ))
Out [ 85 ]: [ "The Dormouse's story" , "The Dormouse's story" ]
def is_the_only_string_within_a_tag ( s ):
"""Return True if this string is the only child of its parent tag."""
return ( s == s . parent . string )
In [ 87 ]: soup . find_all ( text = is_the_only_string_within_a_tag )
Out [ 87 ]:
[ "The Dormouse's story" ,
"The Dormouse's story" ,
'Elsie' ,
'Lacie' ,
'Tillie' ,
'...' ]
虽然text参数用于搜索字符串,还可以与其它参数混合使用来过滤 tag。BeautifulSoup会找到.string属性与text参数值相符的 tag。以下代码用来搜索内容中包含Elsie的<a>标签:
1
2
In [ 88 ]: soup . find_all ( 'a' , text = "Elsie" )
Out [ 88 ]: [ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ]
limit 参数
find_all()方法返回全部的搜索结构,如果文档树很大那么搜索会很慢。如果我们不需要全部结果,可以使用limit参数限制返回结果的数量。当搜索结果的数量达到limit的限制时,就停止搜索返回结果。
1
2
3
4
5
6
7
8
9
10
In [ 89 ]: soup . find_all ( 'a' )
Out [ 89 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
In [ 90 ]: soup . find_all ( 'a' , limit = 2 )
Out [ 90 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ]
recursive 参数
调用 tag 的find_all()方法时,BeautifulSoup会检索当前 tag 的所有子孙节点,如果只想搜索 tag 的直接子节点,可以使用参数recursive=False。
有如下文档:
1
2
3
4
5
6
7
< html >
< head >
< title >
The Dormouse 's story
</ title >
</ head >
...
是否使用recursive参数的结果:
1
2
3
4
5
6
7
8
In [ 95 ]: soup . html . find_all ( 'title' )
Out [ 95 ]:
[ < title >
The Dormouse 's story
</ title > ]
In [ 96 ]: soup . html . find_all ( 'title' , recursive = False )
Out [ 96 ]: []
像调用 find_all()一样调用 tag
find_all()几乎是BeautifulSoup中最常见的搜索方法,所以定义了它的简写方法。BeautifulSoup对象和Tag对象可以被当作一个方法来使用,这个方法的执行结果与调用这个对象的find_all()方法相同。
下面两行代码是等价的:
1
2
soup . find_all ( "a" )
soup ( "a" )
以下两行代码也是等价的:
1
2
soup . title . find_all ( text = True )
soup . title ( text = True )
CSS 选择器
BeautifulSoup支持大部分的 CSS 选择器,在Tag或BeautifulSoup对象的select()方法中传入字符串参数即可使用 CSS 选择器的语法找到 tag:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
In [ 1 ]: from bs4 import BeautifulSoup
In [ 2 ]: html_doc = """
...: <html><head><title>The Dormouse's story</title></head>
...: <body>
...: <p class="title"><b>The Dormouse's story</b></p>
...:
...: <p class="story">Once upon a time there were three little sisters; and their names were
...: <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
...: <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
...: <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
...: and they lived at the bottom of a well.</p>
...:
...: <p class="story">...</p>
...: """
In [ 3 ]: soup = BeautifulSoup ( html_doc , 'lxml' )
In [ 4 ]: soup . select ( 'title' )
Out [ 4 ]: [ < title > The Dormouse 's story</title>]
In [ 5 ]: soup . select ( 'p:nth-of-type(3)' )
Out [ 5 ]: [ < p class = "story" >...</ p > ]
通过 tag 标签逐层查找:
1
2
3
4
5
6
7
8
In [ 6 ]: soup . select ( 'body a' )
Out [ 6 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
In [ 7 ]: soup . select ( 'html head title' )
Out [ 7 ]: [ < title > The Dormouse 's story</title>]
找到某个 tag 标签下的直接子标签:
1
2
3
4
5
6
7
8
In [ 8 ]: soup . select ( 'head > title' )
Out [ 8 ]: [ < title > The Dormouse 's story</title>]
In [ 9 ]: soup . select ( 'p > a' )
Out [ 9 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
找到兄弟节点标签:
1
2
3
4
5
6
7
In [ 14 ]: soup . select ( '#link1 ~ .sister' )
Out [ 14 ]:
[ < a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
In [ 15 ]: soup . select ( '#link1 + .sister' )
Out [ 15 ]: [ < a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ]
通过 CSS 的类名查找:
1
2
3
4
5
6
7
8
9
10
11
In [ 16 ]: soup . select ( '.sister' )
Out [ 16 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
In [ 17 ]: soup . select ( '[class~=sister]' )
Out [ 17 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
通过 tag 的 id 查找:
1
2
3
4
5
In [ 18 ]: soup . select ( '#link1' )
Out [ 18 ]: [ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ]
In [ 19 ]: soup . select ( 'a#link2' )
Out [ 19 ]: [ < a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ]
通过是否存在某个属性来查找:
1
2
3
4
5
In [ 20 ]: soup . select ( 'a[href]' )
Out [ 20 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
通过属性的值来查找:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
In [ 21 ]: soup . select ( 'a[href="http://example.com/elsie"]' )
Out [ 21 ]: [ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ]
In [ 22 ]: soup . select ( 'a[href^="http://example.com/"]' )
Out [ 22 ]:
[ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ,
< a class = "sister" href = "http://example.com/lacie" id = "link2" > Lacie </ a > ,
< a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
In [ 23 ]: soup . select ( 'a[href$="tillie"]' )
Out [ 23 ]: [ < a class = "sister" href = "http://example.com/tillie" id = "link3" > Tillie </ a > ]
In [ 24 ]: soup . select ( 'a[href*=".com/el"]' )
Out [ 24 ]: [ < a class = "sister" href = "http://example.com/elsie" id = "link1" > Elsie </ a > ]
更多有关 CSS 选择器的内容,请参考CSS 选择器参考手册 。
爬取豆瓣电影 TOP250 海报
接下来,通过爬取豆瓣电影 TOP250 海报实践一下。访问豆瓣电影 Top 250
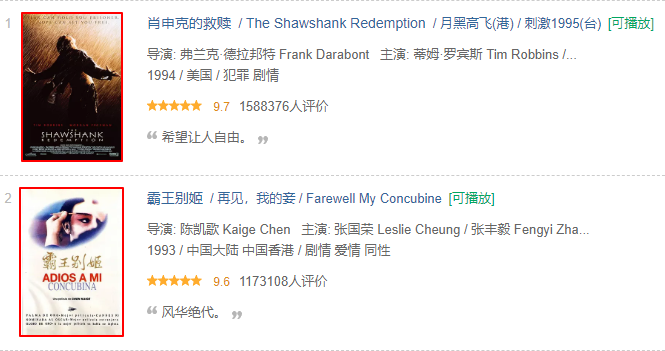
可以看到每部电影左侧都配有一张海报,我们的目的就是下载这些海报到本地。
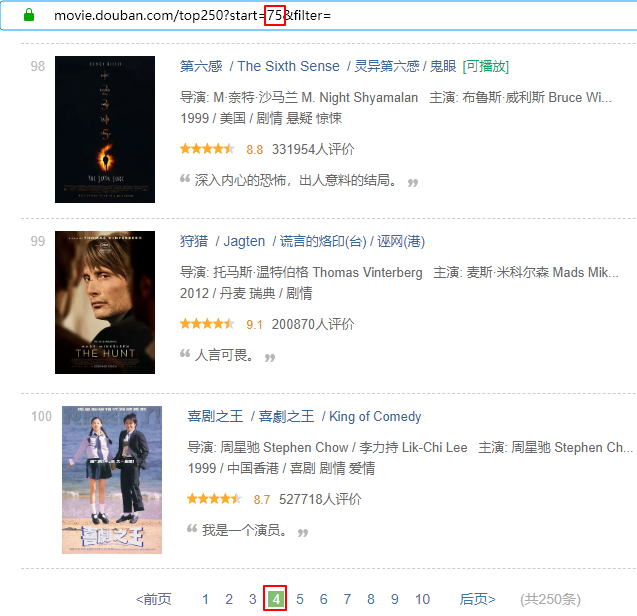
多看几页,就会发现每个页面的 URL 和页号是有关系的。
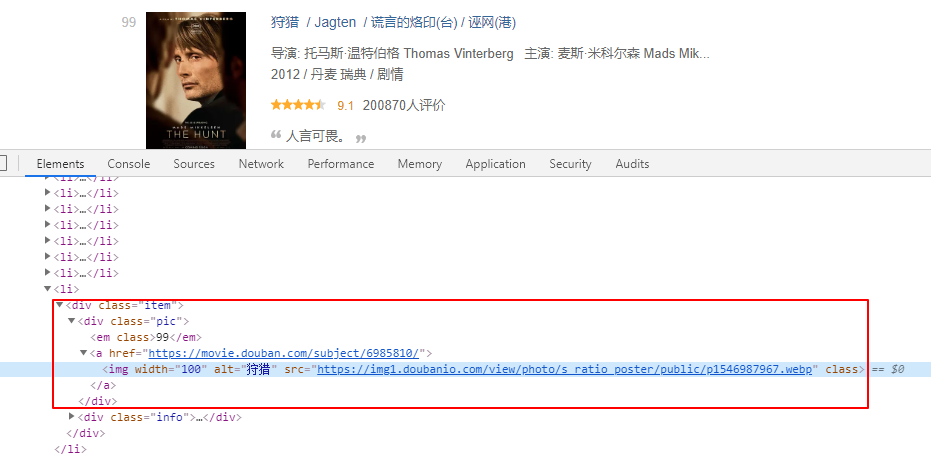
URL 中start这个参数的值等于(页号 - 1) * 25。接下来,再审查一下元素
可以发现海报的地址包含在class值为pic的div元素下,我们可以用BeautifulSoup的select()方法获取到img元素,再提取src属性。代码如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
from urllib.request import urlopen
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from urllib.request import Request
import os
BASE_URL = "https://movie.douban.com/top250?start= {page_id} &filter="
user_agent = UserAgent ()
def get_content ( url ):
"""
根据url发送请求
:param url: 请求url
:return: 响应内容
"""
headers = {
'User-Agent' : user_agent . random
}
request = Request ( url , headers = headers )
response = urlopen ( request )
return response . read ()
def parse_html ( html ):
"""
解析HTML
:param html: HTML文档字符串
:return:
"""
soup = BeautifulSoup ( html , 'lxml' )
items = soup . select ( ".pic img" )
for item in items :
yield item . get ( "src" )
def save_image ( image_url , file_name , folder = 'images' ):
"""
保存图片
:param image_url: 图片地址
:param file_name: 文件名
:param folder: 保存目录
"""
image = get_content ( image_url )
if not os . path . exists ( folder ):
os . mkdir ( folder )
file_name = " {} / {} .jpg" . format ( folder , file_name )
with open ( file_name , 'wb' ) as f_obj :
f_obj . write ( image )
print ( "保存:" , file_name )
def main ():
total = 0
for i in range ( 20 ):
url = BASE_URL . format ( page_id = i * 25 )
html = get_content ( url ) . decode ( 'utf-8' )
for image in parse_html ( html ):
print ( "下载:" , image )
save_image ( image , total )
total += 1
if __name__ == '__main__' :
main ()
运行结果如下:
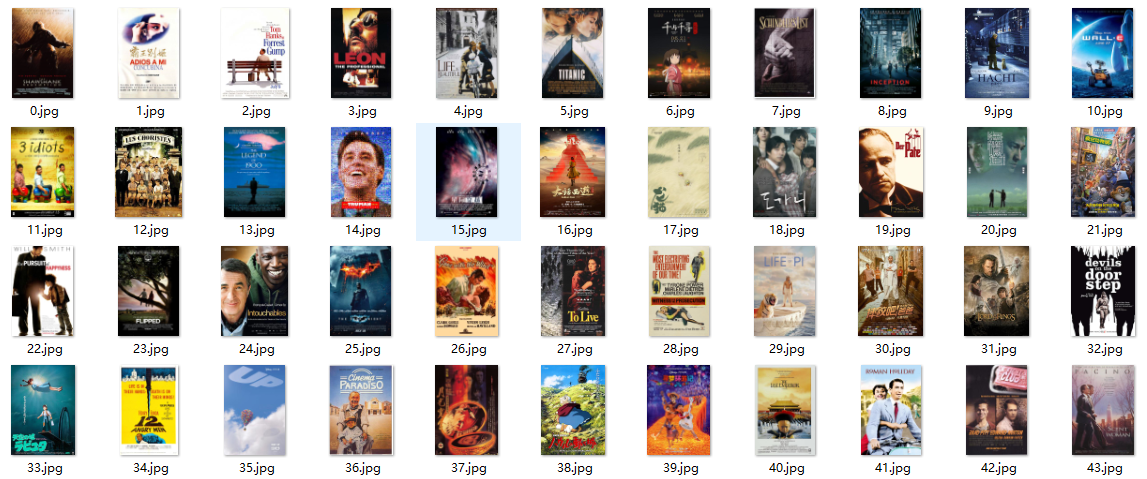
最后,可以将所有的海报拼接起来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import math
import PIL.Image as Image
def merge_images ( folder , size = 1000 ):
"""
将folder目录下的图片按尺寸size拼接
:param folder: 图片
:param size: 尺寸
"""
images_count = len ( os . listdir ( folder ))
each_size = int ( math . sqrt ( size * size / images_count )) - 1
lines_count = int ( size / each_size )
final_image = Image . new ( 'RGB' , ( size , size ), 'white' )
row , column = 0 , 0
for i in range ( images_count ):
image_path = " {} / {} .jpg" . format ( folder , i )
try :
image = Image . open ( image_path )
except IOError as e :
print ( image_path , "出错啦!!!" )
else :
image = image . resize (( each_size , each_size ))
final_image . paste ( image , ( row * each_size , column * each_size ))
column += 1
if column == lines_count :
column = 0
row += 1
final_image . save ( " {} / {} .jpg" . format ( folder , "final_image" )))
得到:
总结
本文我们介绍了BeautifulSoup库的一些内容,它可以将 HTML/XML 文档进行解析,得到一个文档树
树中的每个节点都是BeautifulSoup四种对象中的一种。可以用find_all()或select()找到我们需要查找的节点。之后,可以通过节点的属性或者方法获取到我们需要的信息。
参考


 支付宝
支付宝
 微信
微信